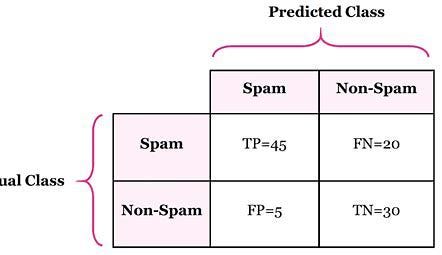
Features (human experience)

Features (machine learning)

Text Processing

Image processing

Speech processing
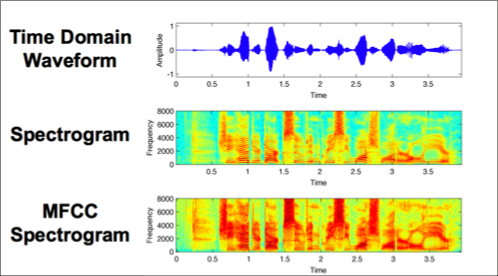
Feature detection
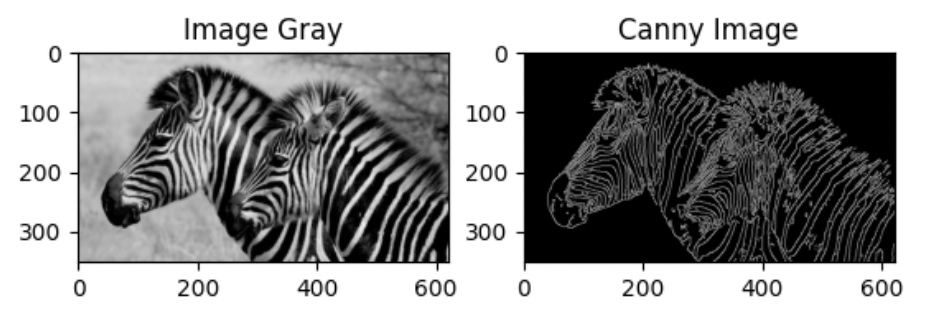
Canny edge detector is an old-school powerful means for contour feature extraction / detection.
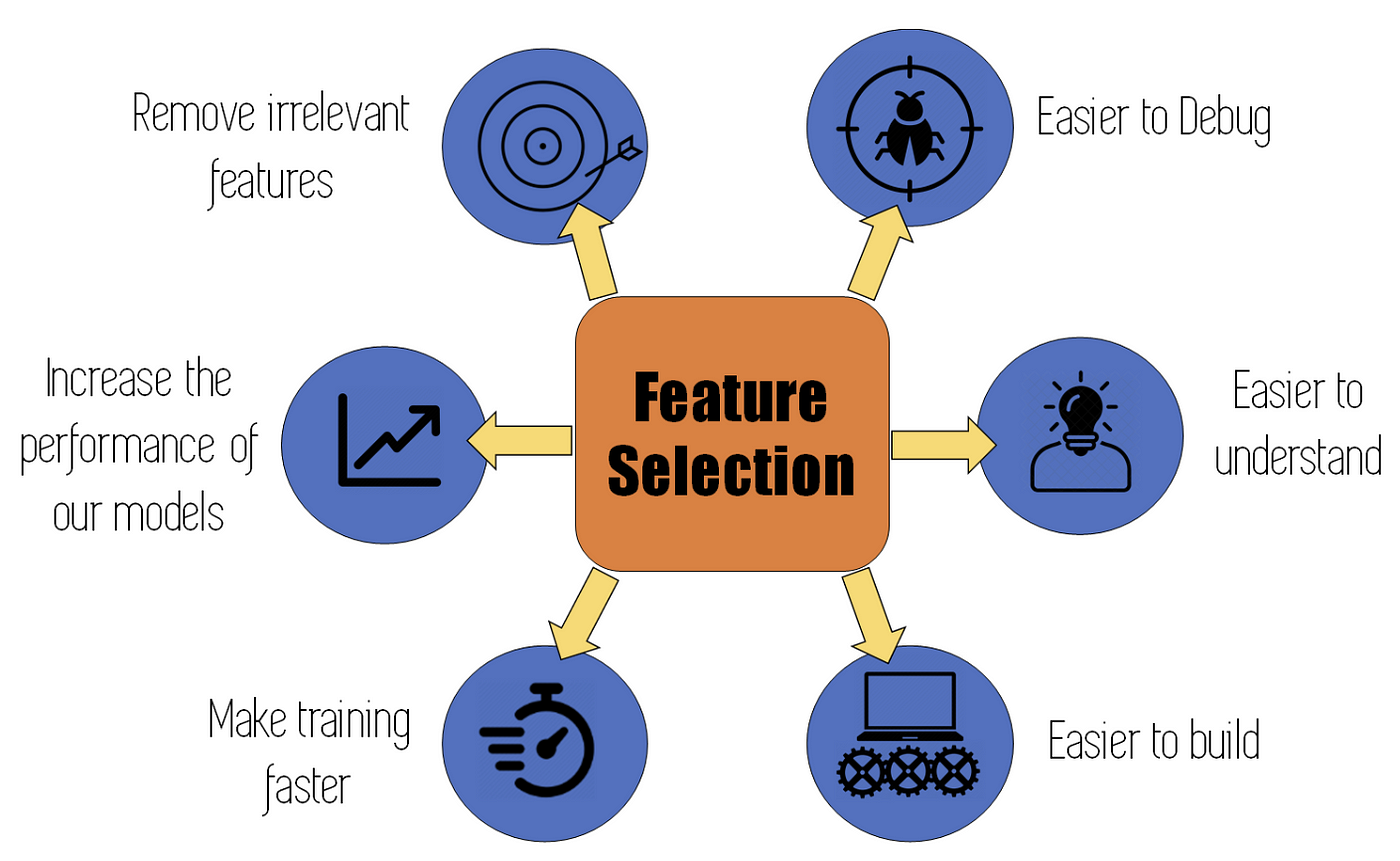
Feature selection
Testing

Supervised learning & Human learning
Categorization
Classifiers
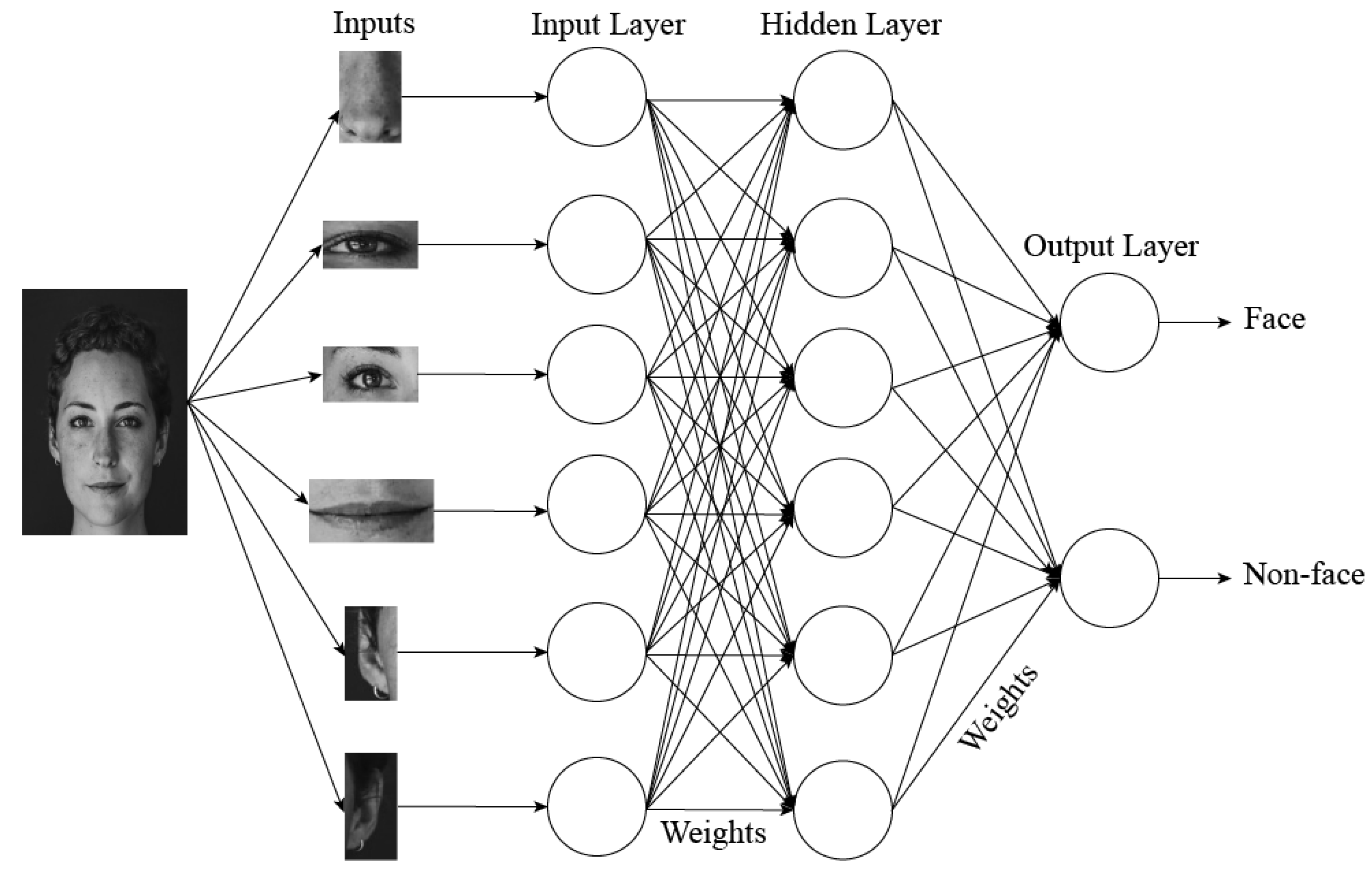
Support Vector Machines
Decision Trees

Exercicio: AI Unplugged 1
Training

Evaluation